2025-01-10 09:01:17
小程序引入第三方js,这些技巧你知道吗?
Ubuntu 压缩文件超全攻略,看这一篇就够了!
一文搞懂JS数字向上取整,码住不亏!
还在为Java日期加一而烦恼?看这一篇就够了!
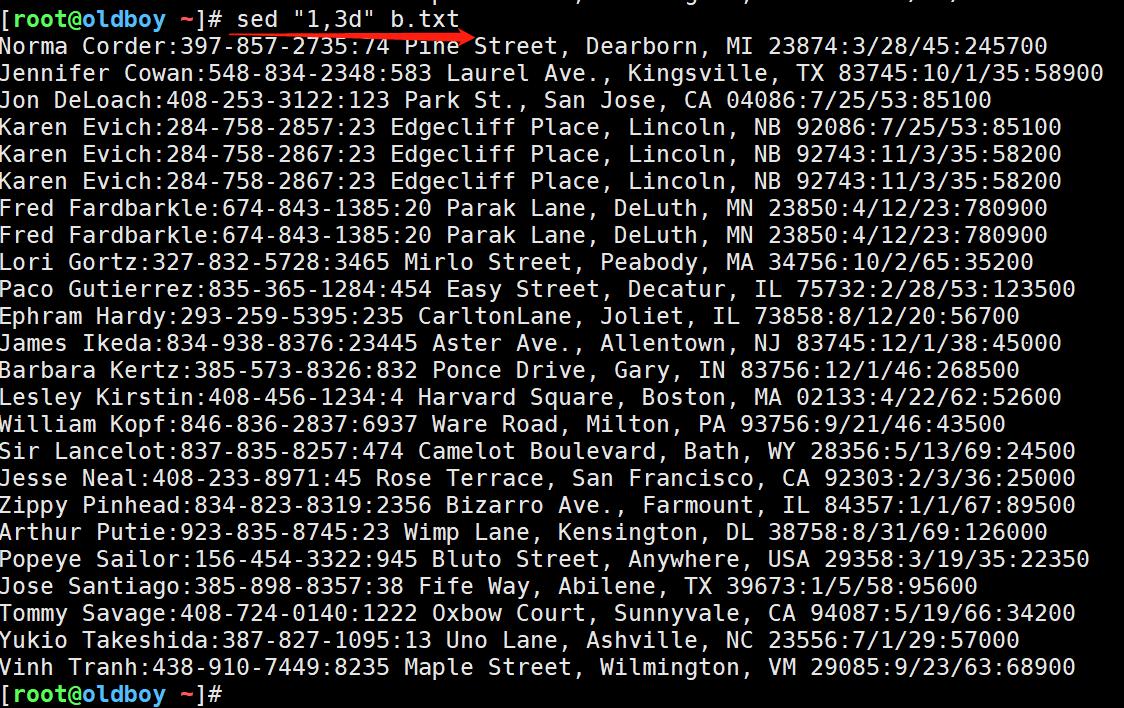
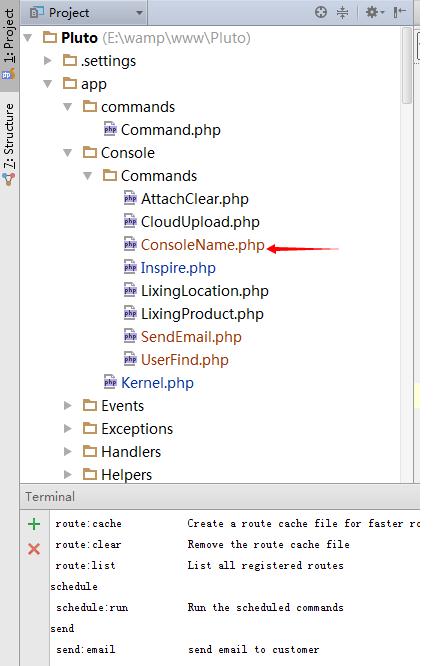
Laravel 打印 SQL,超实用教程来袭!
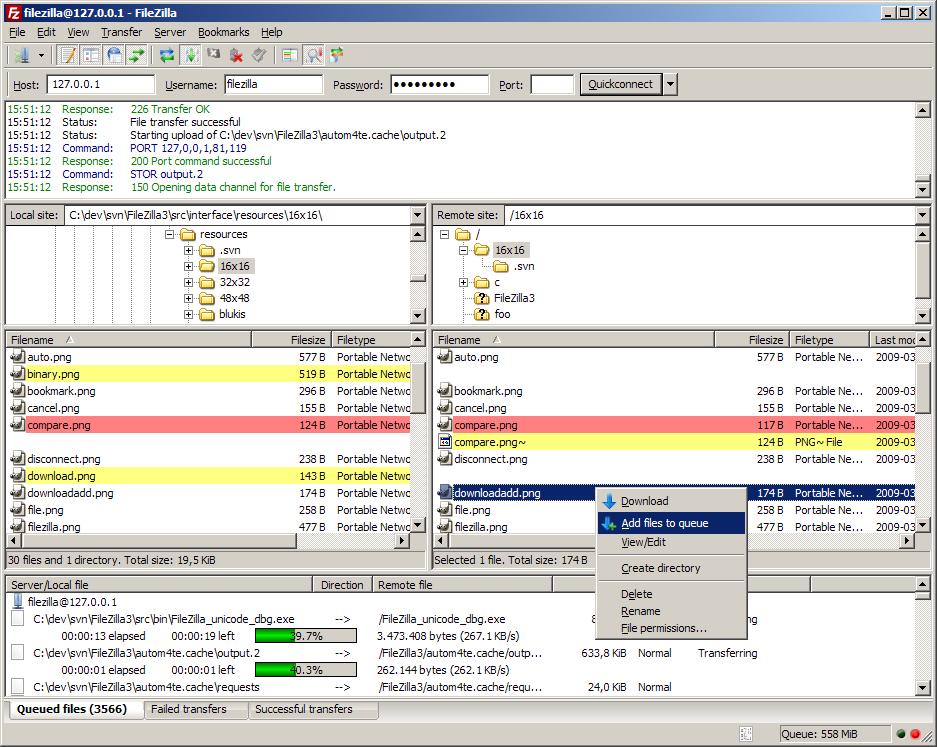
Filezilla连不上服务器?别急,看这篇就够了!
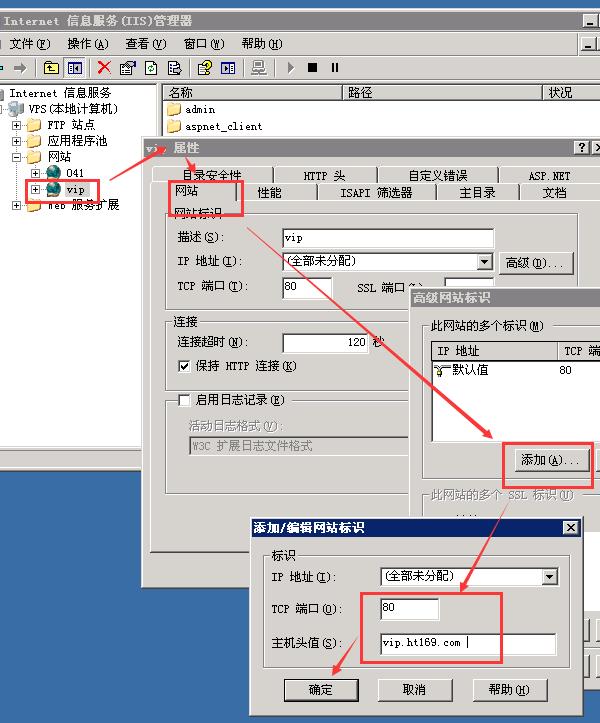
还不会设置虚拟IP地址?看这一篇就够了!
CentOS 7查看开放端口,看这一篇就够了!
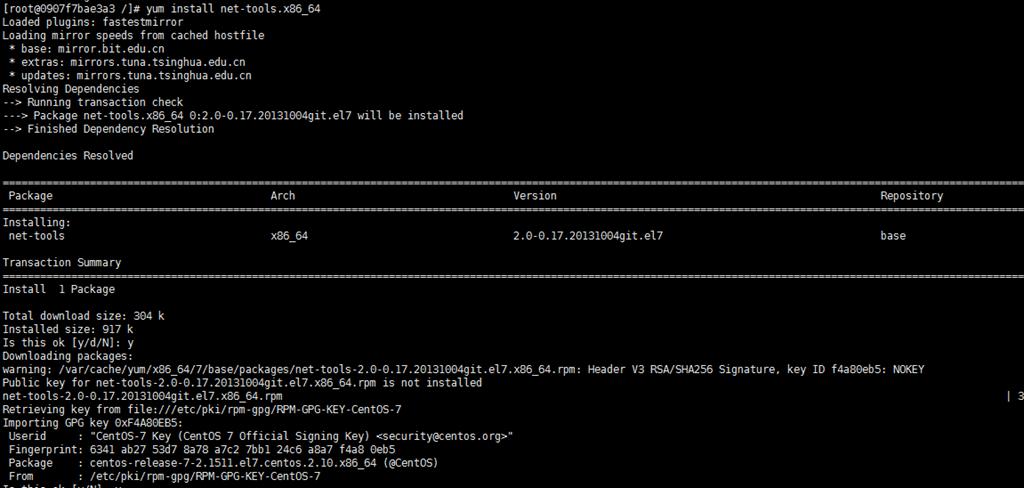
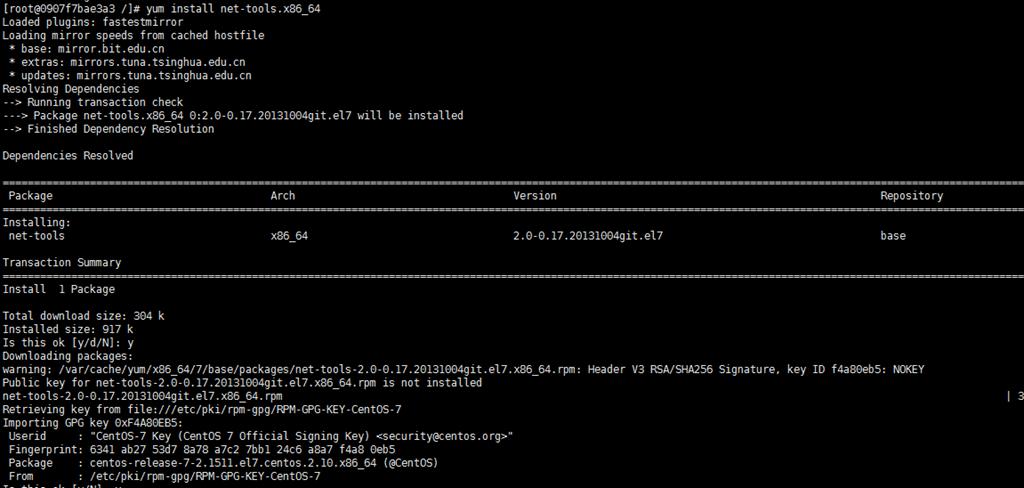
Ubuntu系统安装ifconfig,看这一篇就够了!
内蒙古SEO优化全攻略,让你的网站“C位出道”
服务微信|南昌墨韵