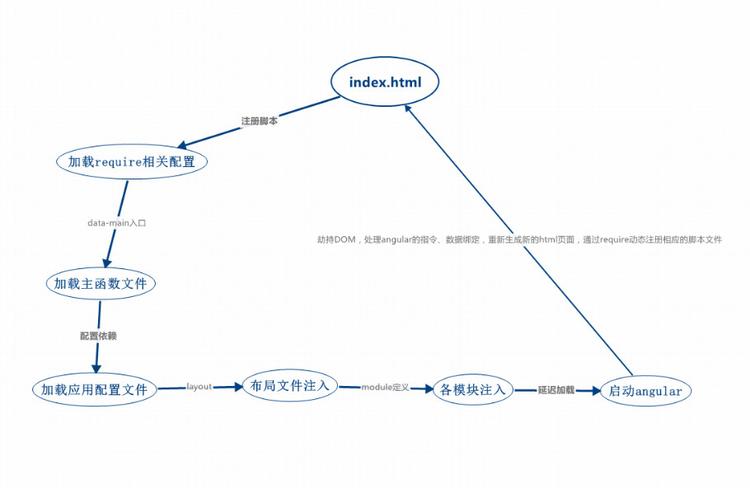
在 Python 里,实现列表相减最简单直接的办法就是用减号运算符 “-”。它的逻辑就像是从一个装满宝贝的宝箱(第一个列表)里,把另一个清单(第二个列表)上列着的宝贝挑出去,最后剩下的就是相减的结果啦。给你看段代码就明白了:在这段代码里,list1 是咱们的 “大宝箱”,list2 是要挑出去的 “清单”。通过列表推导式 [x for x in list1 if x not in list2],咱们挨个检查 list1 里的元素,只要它不在 list2 里,就把它留下来放进新的列表 result 中。最后打印出来的 [1, 2] ,就是 list1 减去 list2 的 “剩余宝藏” 咯。是不是挺简单的?不过这里面可有个小细节得注意,列表相减是按元素的值来判断的,和元素在列表里的位置没啥关系哦。
说到这儿,咱得把列表推导式和利用集合做差集这两种主流方法放一起 “掰扯掰扯”,看看啥时候用哪种更合适。从代码简洁度来讲,列表推导式那是相当亮眼,就一行代码,逻辑清晰明了,像个小巧玲珑的瑞士军刀,简单场景下用它,能快速解决问题,代码看起来也清爽。比如说,你就想从一个同学名字列表里去掉几个特定名字,直接用列表推导式 [name for name in student_list if name not in specific_names] ,一目了然。可要是数据量大了,情况就有点不一样啦。利用集合做差集的优势就凸显出来了。因为集合底层的存储和运算机制,让它在处理大规模数据时,速度就像坐了火箭。就好比你要处理两个各有上千个元素的列表,用集合差集操作 list(set(big_list1) - set(big_list2)) ,眨眼功夫就能出结果,比列表推导式快上好多。不过呢,它也有个小 “瑕疵”,就是转换为集合再转换回列表,这一来一回,原始列表的顺序可就保不住了。所以啊,要是你的数据量不大,又特别在意列表顺序,列表推导式是首选;要是数据量 “爆棚”,对运行效率有极高要求,那用集合来做差集运算准没错,至于顺序问题,后续再想办法调整就行啦。这就好比出门旅行,短途游带个轻便背包就行,长途跋涉可就得选个大容量的旅行箱咯,合适的工具才能让咱的编程之旅更顺畅。